
前置知识:范式转移”(paradigm shift)
从“节省CPU计算”转变为“减少内存访问 + 利用并行计算。
注:整理自《游戏引擎架构》 第二版
在早期的计算机中,CPU的效率低下,因此核心的优化在于少去计算
而如今,情况反过来了,CPU的计算非常快,且可以多核,真正的瓶颈变成了内存,内存的访问速度远跟不上CPU,因此出现了一个经典说法:“内存访问昂贵,计算便宜”
所以,要多做计算,尽量减少内存访问。 比如:
1 | data = list(range(10_000_000)) |
与
1 | n = 10_000_000 |
方案二的花费时间要少得多
缓存的概念
缓存也是内存的一部分,但离CPU非常近,且采用了最贵以及最快的技术,这两个因素导致了缓存的容量远小于内存。
通常结构:
1 | L1 Cache:最小、最快、离CPU最近 |
内存缓存系统提升内存访问性能的方法是,将程序最常使用的数据块保存至缓存的局部
拷贝(local copy)。若CPU请求的数据已存在于缓存中,缓存就能非常快速地完成请求,通常是数十个周期的数量级,此情况称为缓存命中(cachehit)。然而,若数据未置于缓存中,那么必须从主内存读人缓存,这被称为缓存命中失败(cache miss)。从主内存读数据可能需花数千个周期,因此缓存命中失败的确会带来非常高的开销。
缓存命中失败是什么
CPU要数据 → 先去缓存找
如果找到了 → 命中(hit)
如果没找到 → 命中失败(miss) → 去内存拿(很慢)
所以:
cache miss = CPU在缓存里没找到想要的数据
缓存的层级结构
就像这样:
1 | CPU |
为什么这样做?
因为一个核心矛盾:
缓存越快 → 越小 → 越贵
你不可能:又要超快、又要超大
所以工程师做了一个折中:用多层缓存来平衡速度和容量
如何减少命中失败的代价?
如果不存在分级:CPU miss → 直接去内存(超慢)
有分层:
1 | CPU |
本质:不是减少 miss 次数,而是减少 miss 的“代价”
此外,缓存不是按“一个变量”读,而是按“块(cache line)”读
缓存空间远小于内存 → 必须“复用位置”(映射)
一个缓存位置会对应很多内存地址(冲突来源)
缓存线
缓存控制器会读取“多于所请求的内存”
比如:
1 | 不是这样: |
这“一整块”就是:缓存线(cache line)
为什么这样设计
程序通常是顺序访问的:
1 | for i in range(100): |
访问 arr[0] → 顺便把 arr[1~15]带进缓存,后面访问直接命中,这就是“空间局部性”
缓存和内存的“映射关系”
缓存大小远小于内存 → 一个缓存位置要重复使用
我们假设:Cache:32 KiB,Cache line:128B,其中,32KiB = 32768字节 32768/128 = 256,因此,一共有 256 条缓存线(32KB 的空间能放多少个 128B 的格子?
→ 256 个),再假设主内存为256 MiB,结果是什么?内存比缓存大 8192倍
所以:同一个缓存位置,要轮流存8192个不同的内存块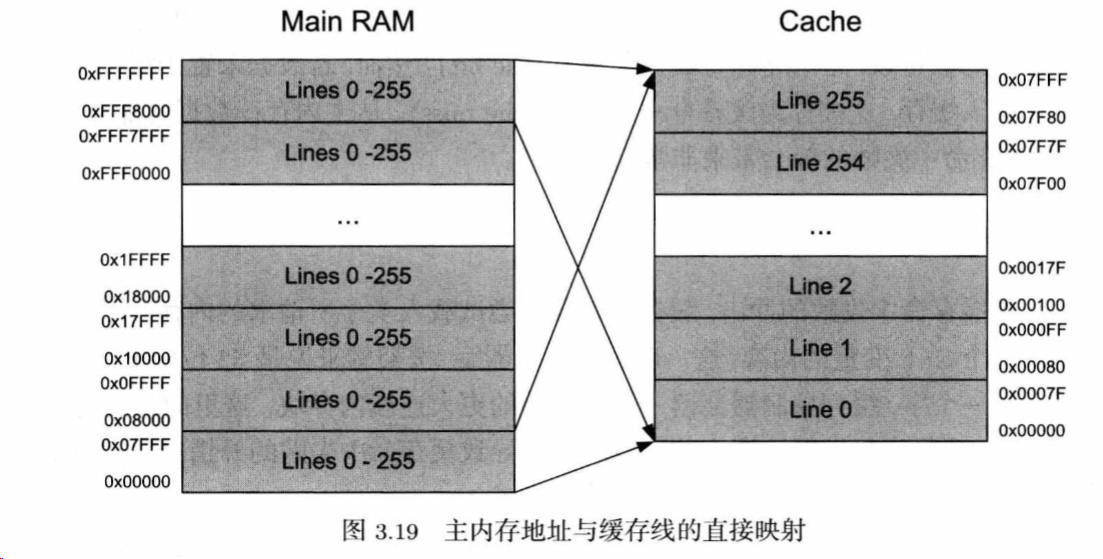
直接映射:主内存很多块 → 映射到缓存的固定位置
比如:
1 | 内存地址: |
都映射到同一个位置!
冲突因此而来
例子:
1 | arr[0] |
如果它们:
映射到同一个 cache line
那么:
1 | 访问 arr[0] → 放进cache |
来回抖动 → 性能灾难
地址如何映射?
用地址“取模”缓存大小
cache_index = 地址 % cache大小
决定它放哪个缓存槽
然后地址会被拆成三部分:
1 | [ tag | index | offset ] |
offset:在cache line里的位置
index:在哪条cache line
tag:验证是不是你要的数据
一句话总结:缓存线解决“效率问题”,映射机制引入“冲突问题”