
游戏开发中如何优化动态内存分配
malloc/free(或 new/delete)很慢,原因有两个:
- 通用性太强:要处理各种大小、碎片、对齐等情况
- 可能触发系统调用:甚至导致内核态切换(context switch)
所以游戏开发经验:尽量减少堆分配,尤其不要在高频循环里用
如何解决
1.预分配大块内存
一次性申请一大块内存,后续都在这块里面“切分使用” 👉 避免频繁 malloc/free
2️.按使用模式优化(关键)
不同场景用不同分配策略,比如:栈式(LIFO)、池式(固定大小)、双端栈等
栈式分配器(StackAllocator)
核心思想(像“栈”一样用内存)
👉 分配:往前“推”
👉 释放:只能“回退”
就像函数调用栈一样(先进后出)
分配方式:
1 | void* alloc(U32 size_bytes); |
每次分配:从当前“栈顶”拿一块,指针向前移动
限制:不能随便 free 某一块内存!
只能:一次性回退或按顺序释放
Marker 机制
1 | Marker getMarker(); |
怎么理解?👉 Marker = 当前内存位置的“书签”
使用流程:
- 分配一些内存
- 记录一个 marker
- 再分配一些内存
- 想释放?直接回到 marker
等价于:
1 | [ A ][ B ][ C ][ D ][ E ] |
执行 freeToMarker 后:
1 | [ A ][ B ] |
👉 C、D、E 全部一次性释放
优点 vs 缺点
✅ 优点
- 极快(几乎就是指针移动)
- 无碎片
- cache 友好
❌ 缺点
- 不灵活(必须按顺序释放)
- 不适合复杂生命周期对象
双端栈分配器
升级版👇
👉 一块内存,两头都可以分配:
1 | 低地址 ←——— 内存块 ———→ 高地址 |
特点:一边往右长,一边往左长
👉 用途:两类生命周期不同的数据
比如:一边:长期资源,一边:临时数据
池分配器(Pool Allocator)
核心思想:把内存切成很多“固定大小的小块”,重复利用
为什么需要它?
很多对象:大小固定(比如:粒子、子弹、节点)且创建/销毁频繁
👉 用 malloc/free:慢、会产生碎片
🧩 怎么做?
第一步:申请一大块内存
1 | [ 整块内存 ] |
第二步:切成小块(chunk)
1 | [ ][ ][ ][ ][ ][ ] |
每块大小一样(比如 32 bytes)
第三步:用“空闲链表”管理
👉 每个空闲块里,存“下一个空闲块的指针”
1 | free list: |
分配过程:
1 | alloc(): |
O(1),超级快
释放过程:
1 | free(ptr): |
也是 O(1)
“没有分配的内存块本身就用来存链表指针”
也就是:不用额外结构,内存自己管理自己
限制:只能分配固定大小,不适合大小变化的对象
适用场景:粒子系统、子弹对象、ECS组件、网络包结构
内存对齐
什么是“对齐”?
👉 数据地址必须是某个数的倍数
比如: 4字节对齐 → 地址 % 4 == 0;16字节对齐 → 地址 % 16 == 0
为什么要对齐?
1.CPU要求 某些CPU不对齐会:性能下降,甚至崩溃
2.SIMD / GPU / DMA 比如:SSE / AVX 要求 16 / 32 字节对齐,GPU buffer 也有要求
问题来了,普通 malloc 不一定满足高对齐(比如16字节以上)
所以需要:aligned allocation(对齐分配)
对齐分配的实现原理(重点)
申请内存,使返回地址满足:
1 | address % alignment == 0 |
aligned = (raw + alignment - 1) & ~(alignment - 1);
1 | 意思是 向上取整到 alignment 的倍数 |
[ 原始地址 … 对齐地址 ]
↑
返回给用户
1 | ⬆️这是不对的,因此: |
aligned[-1] = adjustment
1 | 这样在释放时: |
就能成功找回原始 malloc 指针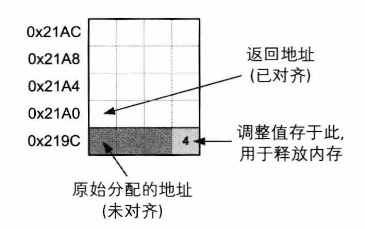
1 | malloc 得到 raw 地址 |
| 分配器 | 特点 | 适用 |
|---|---|---|
| 栈分配器 | 快,但只能顺序释放 | 临时数据 |
| 池分配器 | 固定大小,O(1) | 小对象 |
| 对齐分配 | 满足硬件要求 | SIMD / GPU |
按帧管理临时内存
分为:
- 单帧分配器(single-frame allocator)
- 双缓冲分配器(double-buffered allocator)
它们本质上都是前面“栈式分配器”在游戏主循环里的具体用法。
为什么会有?
在游戏中,一般的流程是:
1 | while (true) { |
每一帧里都会产生很多临时数据,比如:碰撞检测临时结果、可见性裁剪列表、渲染命令缓存、动画混合中间结果、AI 搜索临时节点
这些数据通常有两种生命周期:只在当前帧有效 或 当前帧生成,下一帧还要继续用
所以就有了这两个分配器。
单帧分配器(Single-Frame Allocator)
核心思想
每一帧开始时,把整块临时内存“清空”,本帧里只管分配,不单独释放。
它其实就是一个普通的 StackAllocator:
帧开始:clear()
帧内:不断 alloc()
帧结束:什么都不用管
下一帧开始:再 clear()
优点:
- 非常快,只需要移动栈顶指针。
- 没有碎片,因为根本不是零散释放。
- 编程简单,不用操心一块块 free。
从这里分配出来的内存,只能在当前帧内使用。因为下一帧一开始就 clear() 了,之前的指针全部失效。
所以程序员必须很小心:
- 不能把这些指针保存到长期对象里
- 不能跨帧访问
- 不能把它当普通堆内存用
双缓冲分配器
双缓冲分配器解决的问题是: 有些临时数据虽然不是永久的,但需要跨一帧。
比如:
- 第 i 帧生成的数据,第 i+1 帧还要读
- 异步任务本帧开始,下一帧才结束
- GPU / SPU / 其他线程正在使用上一帧的数据
这时候单帧分配器就不够了,因为它一到下一帧就清空。
它本质上是准备两个单帧栈,交替使用:
m_stack[0]
m_stack[1]
当前帧只往其中一个里分配。到下一帧时:
- 交换当前缓冲区
- 清空新的当前缓冲区
- 旧缓冲区保留不动,供上一帧数据继续使用
核心逻辑
1 | swapBuffers(); // 0 和 1 互换 |
m_curStack = !m_curStack; 这一句就是在 0 和 1 之间来回切换。
为什么叫“双缓冲”
因为和图形学里的双缓冲思想是一样的:
一个缓冲区负责“当前写入”,另一个缓冲区负责“上一帧继续被读取” ,下一帧两者交换。
所以它能保证:本帧写新数据时,不会覆盖上一帧仍在使用的数据
对于游戏循环里的临时数据,最好的办法不是“精细地一个个释放”,而是根据数据的生命周期,按帧批量回收。
所以:
- 当前帧就死的数据 → 单帧分配器
- 还要保留到下一帧的数据 → 双缓冲分配器